去年这个时候我刚开始写现代密码学的博客,过了一年开了个这个,令人感叹。
配环境
第一次配环境的时候wsl给我搞崩了,可能是wsl的Ubuntu版本不同,导致源和官方文档不太一样。反正没什么重要东西,卸载重装_(:з)∠)_
具体方法详见官方文档,我自己的环境配置为:
wsl2+Ubuntu20.04
具体环境及配置命令同官方文档。
一些命令
-
make qemu启动qemu以及xv6。
课程评测文件grade-lab-util是py文件,所以既可以用./grade-lab-util xxxx评测,也可以加个python启动。 -
echo "add-auto-load-safe-path /home/remake/remake_dev/xv6-labs-2021/.gdbinit" >> ~/.gdbinit让gdb-multiarch可以调试xv6程序。调试时需要注意make qemu的flag添加(
Lab 1 Util
主要通过类POSIX接口实现用户的一些功能。
课程
大体其实和普通的OS差不多,但6.S081的一大特点是上来就讲代码,因此很多操作系统课不会讲的代码具体实现在课程里会详细介绍。
除了xv6代码的细节,例如程序必须exit(0)退出,exec载入elf格式文件等,值得讲的就是fork和exec的I/O和File的descriptors,一切似乎都是水到渠成。
file descriptor作为一种流的抽象,被广泛应用于UNIX的各个部分(除了network,虽然有类似实现但又存在不同),诸如管道等。
fork在普通OS课程中只会用变量等例子来展示"子进程是父进程的复制",但不仅于此。fork在复制程序本身的情况下还复制了父进程的文件描述符表,而exec虽然改变了程序(通过load的image),但不会对文件描述符表进行改变。
因此,父进程可以通过临时改变文件描述符来操作子进程的描述符,子进程只知道描述符本身,而不知道描述符后面代表的是文件,设备、或者管道。
另外,fork虽然复制了描述符表,但每个描述符下的偏移量是独立的。因此,两个进程的描述符下可能是同一个东西,共享同一个偏移量。
既然介绍了这么多,那么pipe也就水到渠成了。父进程和子进程共享一个descriptor。在实际的操作中,一端操作需要对另一端进行关闭,否则便会一直阻塞。pipe的语义中,read返回需要:
- write字节
- 写入端关闭
因此,需要按需关闭pipe。
最后一个可以关注的点便是shell内置命令。Unix时代经常把mkdir等命令内置,但Unix将其作为可执行程序,从PATH中寻找。但cd命令不同,如果用传统的fork-exec来进行,改变的只有子进程的工作目录,shell并不会关注子进程的这一信息。
Sleep (easy)
简单的系统调用。
#include "kernel/types.h"
#include <user/user.h>
void my_sleep(const char* argument){
int sleep_second = atoi(argument);
sleep(sleep_second);
}
int main(int argc, char const *argv[]){
if(argc <= 1){
fprintf(2, "usage: sleep need number(second).\n");
exit(1);
}
if(argc >=3){
fprintf(2, "error: too many argument.(sleep)\n");
}
my_sleep(argv[1]);
exit(0);
}pingpong (easy)
简单的进程间通信,理解了pipe和fork的关系就行。
//Simple pingpong: pipe.
#include <kernel/types.h>
#include <user/user.h>
int main(int argc, char const *argv[]) {
int p[2];
char buf[2];
if(pipe(p)<0){
fprintf(2, "error: pipe exit(pingpong)\n");
exit(1);
}
int pid = fork();
if(pid == 0){
//child
int read_bytes = read(p[0], buf, 1);
close(p[0]);
if(read_bytes>0){
int now_pid = getpid();
printf("%d: received ping\n", now_pid);
write(p[1], buf, 1);
close(p[1]);
} else {
exit(1);
}
} else if(pid>0){
//parent
char *buf="y";
char* buf_test="y";
write(p[1], buf, 1);
close(p[1]);
int read_bytes = read(p[0], buf, 1);
close(p[0]);
if(read_bytes>0){
int now_pid = getpid();
if(strcmp(buf, buf_test)){
printf("%d: received pong\n", now_pid);
}
}
} else {
fprintf(2, "error: fork(pingpong)\n");
}
return 0;
}primes (moderate)/(hard)
抽象起来了。
问题在于理解下面这张图:
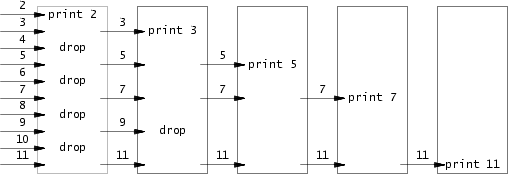
可以看到,主进程fork完后,便一直向子进程发送递增数据,而子程序接受数据后,需要视情况fork,然后传递数据。
其主要伪代码为:
p = get a number from left neighbor
print p
loop:
n = get a number from left neighbor
if (p does not divide n)
send n to right neighbor#include <kernel/types.h>
#include <user/user.h>
void prime(int*fd){
int p, d;
close(fd[1]);
if(read(fd[0], &p, 4)==0){
exit(0);
}
printf("prime %d\n", p);
if (read(fd[0], (void *)&d, sizeof(d))){
int fd1[2];
pipe(fd1);
if (fork() == 0){
prime(fd1);
}else{
// 关闭读
close(fd1[0]);
do{
if (d % p != 0){
write(fd1[1], (void *)&d, sizeof(d));
}
}while(read(fd[0], (void *)&d, sizeof(d)));
// 关闭读
close(fd[0]);
// 关闭写
close(fd1[1]);
wait(0);
}
}
exit(0);
}
int main(int argc, char const *argv[]) {
int p[2];
pipe(p);
int pid=fork();
if(pid==0){
prime(p);
} else if(pid>0){
close(p[0]);
for(int i = 2;i<=35;++i){
write(p[1], &i, 4);
}
close(p[1]);
wait((int*)0);
} else {
fprintf(2, "error: fork(prime).\n");
}
exit(0);
}当时犯了两错误。
- 题目一眼用函数递归实现,但当时钻了牛角尖非得在main函数实现,甚至打算用goto了。
- 函数顺序应该是
read -- read -- fork,这样第二个read便可以成为停止条件;而我当时理解成了read -- fork -- read这会导致一个进程一直在等待信息,从而无法退出程序。
xargs (moderate)
注意读题(
本题并没有什么难度,但做的时候读错题意导致后面代码可读性很差,最后还是参考了别人,令人感叹。
注意要用exec实现,第一次实现的时候虽然过了但并不是exec实现。
#include <kernel/types.h>
#include <kernel/param.h>
#include <user/user.h>
void copy(char **p1, char *p2){
*p1 = malloc(strlen(p2) + 1);
strcpy(*p1, p2);
}
int readline(char** parm, int begin){
char buf[512];
int i = 0;
while(read(0, buf+i, 1)){
if(buf[i]=='\n'){
buf[i]=0;
break;
}
++i;
}
if(i==0){
return 0;
}
int j = 0;
while(j<i){
if(begin>MAXARG){
fprintf(2, "too many parameters!(xargs)\n");
exit(1);
}
int temp = j;
while((j<i)&&(buf[j]!=' ')){
++j;
}
buf[j++] = 0;
copy(&parm[i], buf+temp);
}
return begin;
}
int main(int argc, char *argv[])
{
if(argc<2){
fprintf(2, "Please enter more parameters.(xargs)\n");
exit(1);
}
char*pars[MAXARG];
for(int i = 1;i<argc;++i){
copy(&pars[i-1], argv[i]);
}
int end;
end=readline(pars, argc-1);
while(end){
pars[end]=0;
if(fork()==0){
for(int i =0;i<end;++i){
printf("%s\n", pars[i]);
}
//exec(pars[0], pars);
exit(1);
} else {
wait(0);
}
end=readline(pars, argc-1);
}
exit(0);
}Lab 2 system calls
课程
似乎从lab2开始,便深入xv6细节,而不关注UNIX等其他系统的接口了(但xv6还是类UNIX嘛)
misc
qemu模拟器模拟了ROM, RAM, Disk和 serial connection to 用户的屏幕/键盘。
RISC-V具有三个模式:machine supervisor和user mode,一般的特权指令是指supervisor mode,user space要调用系统调用的时候,需要在寄存器先设置好参数,再通过ecall指令到特权模式,通过sret退出。
xv6的地址空间为39bit,而xv6只用其中的38bit。逻辑空间最大值MAXVA=$2^{38}-1$。
进程抽象为proc结构,其中存储着诸如pagetable等成员。同时,进程维护着两个堆栈,用户堆栈和内核堆栈kstack,内核堆栈在进入特权模式下使用且独立,因此进程破坏的时候,kernel仍然能在kstack中执行。
xv6的启动过程中:
- 首先在bootloader(ROM)读取引导程序,引导程序将xv6 kernel载入内存在_entry中(entry.S):
.section .text
.global _entry
_entry:
# set up a stack for C.
# stack0 is declared in start.c,
# with a 4096-byte stack per CPU.
# sp = stack0 + (hartid * 4096)
la sp, stack0
li a0, 1024*4
csrr a1, mhartid
addi a1, a1, 1
mul a0, a0, a1
add sp, sp, a0
# jump to start() in start.c
call start
spin:
j spinRISC-V(此时为machine mode)启动的时候禁用了分页硬件,因此程序的虚拟地址直接映射入物理地址。
loader直接将kernel映射入物理地址0x80000000,这也是qemu的入口地址。0到80000000的这一部分则是IO设备。
- entry.S创建了C代码所需的栈stack0,并启动了start function(start.c)
- start.c将mode转为supervisor(通过mret)并载入main函数地址(mepc)以及其他必要设置,如委托中断和异常给supervisor mode,启动clock等,最后将pc转为main函数。
- main函数启动必要的配置,在userinit里创建第一个进程。
- 进程执行initcode.S汇编程序,invoke exec 系统调用,转变为/init。当kernel执行exec完毕,将会返回/init 进程,该进程会执行诸如打开标准文件描述符和启动shell等任务。
main函数干了什么?
kinit:设置page allocator kvminit:设置虚拟内存 kvminitstart:打开页表 processinit:设置初始进程 trapinit:设置user/kernel mode转换代码 plicinit:中断控制器 binit:buffer cache fileinit:文件系统 virtio_disk_init:初始化磁盘 userinit:启动第一个进程
System call tracing (moderate)
还是读题问题。英语太差是这样的。
这题讲明了需要在proc结构里增加变量来实现tracing。因此,系统调用trace只需要改变调用进程的mask,fork的子进程便会继承mask(修改fork实现)。
当进行系统调用的时候,syscall函数便会检查mask,默认0,其他情况便可以检查来打印具体函数。
- proc结构里增加mask字段来记录要trace的系统调用。
kernel/syscall.c改为:
void syscall(void)
{
int num;
struct proc *p = myproc();
num = p->trapframe->a7; // 记录系统调用
if(num > 0 && num < NELEM(syscalls) && syscalls[num]) {
p->trapframe->a0 = syscalls[num](); //返回值记录a0
if((1 << num) & p->mask){
printf("%d: syscall %s -> %d\n",
p->pid, sysnames[num], p->trapframe->a0);
}
} else {
printf("%d %s: unknown sys call %d\n",
p->pid, p->name, num);
p->trapframe->a0 = -1;
}
}kernel/sysproc.c添加:
uint64 sys_trace(void)
{
uint64 mask;
if(argaddr(0, &mask)<0)
return -1;
myproc()->mask = mask;
return 0;
}剩余的诸如修改fork和头文件等略。
Sysinfo (moderate)
具体函数用法需要看具体的用例。lab已经给出用法:在kernel/file.c里头。
重要的就是arg函数以及copyout函数使用。
kernel/kalloc.c里增加:
uint64 get_memory_count(void){
uint64 count=0;
struct run*r = kmem.freelist;
while(r){
count+=PGSIZE;
r = r->next;
}
return count;
}kernel/proc.c增加:
int get_process_count(void){
int count = 0;
struct proc* p;
for(p = proc; p < &proc[NPROC]; p++) {
if(p->state != UNUSED){
count++;
}
}
return count;
}kernel/sysproc.c增加系统调用:
uint64 sys_sysinfo(void)
{
uint64 info;
struct sysinfo nowinfo;
if(argaddr(0, &info) < 0)
return -1;
nowinfo.freemem = get_memory_count();
nowinfo.nproc = get_process_count();
struct proc *p = myproc();
if(copyout(p->pagetable, info, (char*)&nowinfo, sizeof(nowinfo))<0)
return -1;
return 0;
}其他修改同trace。
Lab 3
课程
这里试图对xv6的内核页表挂载流程进行梳理。
pre
xv6在c代码中写明了具体的过程。在这之前,先看看用到的结构:
//链表结构
struct run {
struct run *next;
};
//lock并发+freelist结构
struct {
struct spinlock lock;
struct run *freelist;
} kmem;//匿名结构:kmem管理内核页表main函数中关于内核页表的内容有:
kinit(); // physical page allocator
kvminit(); // create kernel page table
kvminithart(); // turn on paging下面内容主要为kalloc.c。
kinit
首先看看kinit:初始化lock和内核页表,将内核页表挂载到物理内存中
void kinit()
{
initlock(&kmem.lock, "kmem");
freerange(end, (void*)PHYSTOP);
}
//end在kalloc.c声明为`extern char []`,实际上的end在kernel.ld出现,其代表内核后的第一个地址.
//PHYSTOP 为宏定义:
#define KERNBASE 0x80000000
#define PHYSTOP (KERNBASE + 128*1024*1024)
//其代表 内存空间为128M.kernel的逻辑地址和物理地址如下所示:
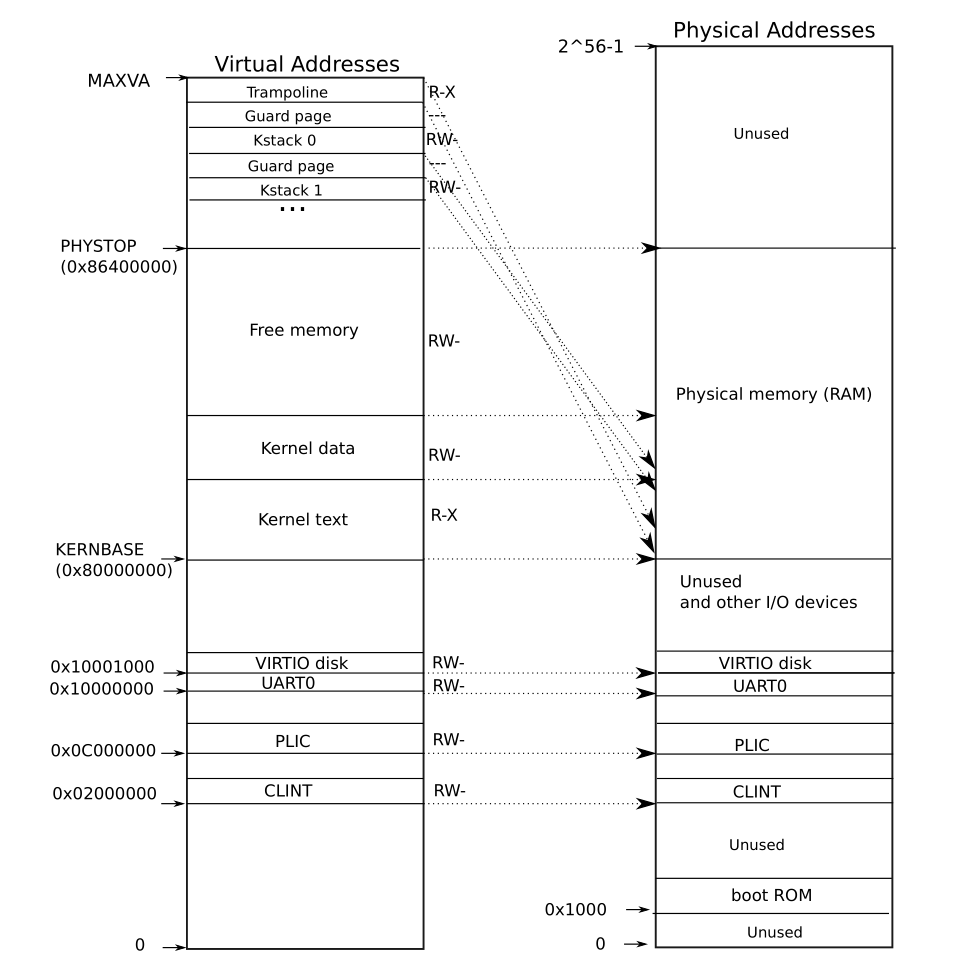
内核挂载在逻辑地址0x8000000(KERNBASE),内核空间到PHYSTOP。由于kinit的时候还未有页表结构,此时的逻辑地址是直接映射到物理空间的。
freerange如下:
#define PGSIZE 4096
#define PGROUNDUP(sz) (((sz)+PGSIZE-1) & ~(PGSIZE-1))
//这里的输入为物理地址
void
freerange(void *pa_start, void *pa_end)
{
char *p;
p = (char*)PGROUNDUP((uint64)pa_start);
for(; p + PGSIZE <= (char*)pa_end; p += PGSIZE)
kfree(p);
}可以看到,以上过程中对pa_start到pa_end的所有空间进行kfree(即初始化)。
xv6中每页长度固定为4096,PGROUNDUP操作的含义是页表首地址往上取整,例如输入(页表0)0000则返回(页表0)0000,若输入(页表0)0001则返回(页表1)0000。
end是kernel后的第一个地址,因此可能没有进行内存对齐。PGROUNDUP则将内核页表的每个页进行内存对齐,内核和内核页表间存在空闲空间。对齐的意义不用多说,其可以简化许多操作,上过计组的都知道罢。
kfree操作如下所示:
void kfree(void *pa)
{
struct run *r;
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
// Fill with junk to catch dangling refs.
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
acquire(&kmem.lock);
r->next = kmem.freelist;
kmem.freelist = r;
release(&kmem.lock);
}kfree 对数据进行必要检查后,memset为1(若错误访问,memset为1期望能够更快地引发异常,终止过程),然后填充链表。
连带着,解释以下kalloc:
void * kalloc(void)
{
struct run *r;
acquire(&kmem.lock);
r = kmem.freelist;
if(r)
kmem.freelist = r->next;
release(&kmem.lock);
if(r)
memset((char*)r, 5, PGSIZE); // fill with junk
return (void*)r;
}kalloc 将free链表的表头去掉free后,初始化内存并返回物理地址(kernel)
kvminit
kvminit紧接着kinit的初始化,开始分配内核页表。
其内部为:
// the kernel's page table.
pagetable_t kernel_pagetable;
void kvminit(void)
{
kernel_pagetable = kvmmake();
}
pagetable_t kvmmake(void)
{
pagetable_t kpgtbl;
kpgtbl = (pagetable_t) kalloc();
memset(kpgtbl, 0, PGSIZE);
// uart registers
kvmmap(kpgtbl, UART0, UART0, PGSIZE, PTE_R | PTE_W);
// virtio mmio disk interface
kvmmap(kpgtbl, VIRTIO0, VIRTIO0, PGSIZE, PTE_R | PTE_W);
// PLIC
kvmmap(kpgtbl, PLIC, PLIC, 0x400000, PTE_R | PTE_W);
// map kernel text executable and read-only.
kvmmap(kpgtbl, KERNBASE, KERNBASE, (uint64)etext-KERNBASE, PTE_R | PTE_X);
// map kernel data and the physical RAM we'll make use of.
kvmmap(kpgtbl, (uint64)etext, (uint64)etext, PHYSTOP-(uint64)etext, PTE_R | PTE_W);
// map the trampoline for trap entry/exit to
// the highest virtual address in the kernel.
kvmmap(kpgtbl, TRAMPOLINE, (uint64)trampoline, PGSIZE, PTE_R | PTE_X);
// map kernel stacks
proc_mapstacks(kpgtbl);
return kpgtbl;
}kvminit调用kvmmake,而kvmmake对每一段进行具体的分配。为什么要这么分配?见上图。
kvmmake:
void kvmmap(pagetable_t kpgtbl, uint64 va, uint64 pa, uint64 sz, int perm)
{
if(mappages(kpgtbl, va, sz, pa, perm) != 0)
panic("kvmmap");
}kvmmap 调用mappages来分配va到pa的满足size=sz的PTE页表项。
mappages
mappages如下所示:
#define PGROUNDDOWN(a) (((a)) & ~(PGSIZE-1))
// Create PTEs for virtual addresses starting at va that refer to
// physical addresses starting at pa. va and size might not
// be page-aligned. Returns 0 on success, -1 if walk() couldn't
// allocate a needed page-table page.
int mappages(pagetable_t pagetable, uint64 va, uint64 size, uint64 pa, int perm)
{
uint64 a, last;
pte_t *pte;
if(size == 0)
panic("mappages: size");
a = PGROUNDDOWN(va);
last = PGROUNDDOWN(va + size - 1);
for(;;){
if((pte = walk(pagetable, a, 1)) == 0)
return -1;
if(*pte & PTE_V)
panic("mappages: remap");
*pte = PA2PTE(pa) | perm | PTE_V;
if(a == last)
break;
a += PGSIZE;
pa += PGSIZE;
}
return 0;
}mappages 通过walk获得分配后的页表项地址,进行一系列检查后持续进行,直到满足size要求。size和va不必进行对齐,函数内部通过PGROUNDDOWN 进行页表项地址向下对齐。
walk
walk用到的宏比较多,这里列出:
#define MAXVA (1L << (9 + 9 + 9 + 12 - 1))
#define PXMASK 0x1FF // 9 bits
#define PXSHIFT(level) (PGSHIFT+(9*(level)))
#define PX(level, va) ((((uint64) (va)) >> PXSHIFT(level)) & PXMASK)
#define PTE2PA(pte) (((pte) >> 10) << 12)
#define PA2PTE(pa) ((((uint64)pa) >> 12) << 10)- MAXVA就是xv6的最高地址,这里分拆来写,maybe让人明白页表和页内偏移的位数吧。
- PX部分通过level和虚拟地址来获得第level级页表项的index。
- PTE2PA的两个组是进行页表项和物理地址的互转。
walk 代码如下:
// Return the address of the PTE in page table pagetable
// that corresponds to virtual address va. If alloc!=0,
// create any required page-table pages.
//
// The risc-v Sv39 scheme has three levels of page-table
// pages. A page-table page contains 512 64-bit PTEs.
// A 64-bit virtual address is split into five fields:
// 39..63 -- must be zero.
// 30..38 -- 9 bits of level-2 index.
// 21..29 -- 9 bits of level-1 index.
// 12..20 -- 9 bits of level-0 index.
// 0..11 -- 12 bits of byte offset within the page.
pte_t *
walk(pagetable_t pagetable, uint64 va, int alloc)
{
if(va >= MAXVA)
panic("walk");
for(int level = 2; level > 0; level--) {
pte_t *pte = &pagetable[PX(level, va)];
if(*pte & PTE_V) {
pagetable = (pagetable_t)PTE2PA(*pte);
} else {
if(!alloc || (pagetable = (pde_t*)kalloc()) == 0)
return 0;
memset(pagetable, 0, PGSIZE);
*pte = PA2PTE(pagetable) | PTE_V;
}
}
return &pagetable[PX(0, va)];
}可以看到,以上过程中相当于模拟了页表的寻址过程。通过三级的页表方式来分配页表,并返回PTE的address。
proc_mapstacks
// Allocate a page for each process's kernel stack.
// Map it high in memory, followed by an invalid
// guard page.
void
proc_mapstacks(pagetable_t kpgtbl) {
struct proc *p;
for(p = proc; p < &proc[NPROC]; p++) {
char *pa = kalloc();
if(pa == 0)
panic("kalloc");
uint64 va = KSTACK((int) (p - proc));
kvmmap(kpgtbl, va, (uint64)pa, PGSIZE, PTE_R | PTE_W);
}
}为每一个proc(proc的内容都是事先分配的)分配一个KSTACK。
KSTACK如下所示:
#define KSTACK(p) (TRAMPOLINE - (p)*2*PGSIZE - 3*PGSIZE)分配KSTACK的时候需要在trampoline下(顶层),每个STACK都要有两个guard pages来保护,若访问了超出KSTACK的部分,有效位会引发异常。
kvminitstart
void
kvminithart(){
w_satp(MAKE_SATP(kernel_pagetable));
sfence_vma();
}执行内存屏障,刷新TLB。
code
2021及之后的6.S081把一些lab改了,怎么回事呢?
Speed up system calls (easy)
本题需要将用户空间(VA)的USYSCALL处映射到内核中的某一处,这样用户便可以从USYCALL处获得必要信息(本题为pid)。
具体实现中:修改proc结构:
kernel/proc.h
struct proc {
struct spinlock lock;
// p->lock must be held when using these:
enum procstate state; // Process state
void *chan; // If non-zero, sleeping on chan
int killed; // If non-zero, have been killed
int xstate; // Exit status to be returned to parent's wait
int pid; // Process ID
// wait_lock must be held when using this:
struct proc *parent; // Parent process
// these are private to the process, so p->lock need not be held.
uint64 kstack; // Virtual address of kernel stack
uint64 sz; // Size of process memory (bytes)
pagetable_t pagetable; // User page table
struct trapframe *trapframe; // data page for trampoline.S
struct context context; // swtch() here to run process
struct file *ofile[NOFILE]; // Open files
struct inode *cwd; // Current directory
char name[16]; // Process name (debugging)
#ifdef LAB_PGTBL
struct usyscall * usyscall;
#endif
};kernel/proc.c:
static struct proc*
allocproc(void)
{
// ......
found:
p->pid = allocpid();
p->state = USED;
// Allocate a trapframe page.
if((p->trapframe = (struct trapframe *)kalloc()) == 0){
freeproc(p);
release(&p->lock);
return 0;
}
#ifdef LAB_PGTBL
if((p->usyscall = (struct usyscall*)kalloc()) == 0){
freeproc(p);
release(&p->lock);
return 0;
}
p->usyscall->pid = p->pid;
#endif
// An empty user page table.
p->pagetable = proc_pagetable(p);
if(p->pagetable == 0){
freeproc(p);
release(&p->lock);
return 0;
}
//.......
}
static void
freeproc(struct proc *p)
{
if(p->trapframe)
kfree((void*)p->trapframe);
#ifdef LAB_PGTBL
if(p->usyscall)
kfree((void*)p->usyscall);
p->usyscall = 0;
#endif
//.....
}
pagetable_t
proc_pagetable(struct proc *p)
{
//....
// map the trapframe just below TRAMPOLINE, for trampoline.S.
if(mappages(pagetable, TRAPFRAME, PGSIZE,
(uint64)(p->trapframe), PTE_R | PTE_W) < 0){
uvmunmap(pagetable, TRAMPOLINE, 1, 0);
uvmfree(pagetable, 0);
return 0;
}
#ifdef LAB_PGTBL
if(mappages(pagetable, USYSCALL, PGSIZE,
(uint64)(p->usyscall), PTE_R | PTE_U)<0){
uvmunmap(pagetable, TRAMPOLINE, 1, 0);
uvmunmap(pagetable, TRAPFRAME, 1, 0);
uvmfree(pagetable, 0);
return 0;
}
#endif
return pagetable;
}
// Free a process's page table, and free the
// physical memory it refers to.
void
proc_freepagetable(pagetable_t pagetable, uint64 sz)
{
uvmunmap(pagetable, TRAMPOLINE, 1, 0);
uvmunmap(pagetable, TRAPFRAME, 1, 0);
#ifdef LAB_PGTBL
uvmunmap(pagetable, USYSCALL, 1, 0);
#endif
uvmfree(pagetable, sz);
}本题的坑在于proc_freepagetable这里。
其余部分的修改均有提示,但proc_freepagetable没有。若未修改proc_freepagetable,则freewalk函数会触发panic:
以下为freewalk(kernel/vm.c)代码:
// Recursively free page-table pages.
// All leaf mappings must already have been removed.
void
freewalk(pagetable_t pagetable)
{
// there are 2^9 = 512 PTEs in a page table.
for(int i = 0; i < 512; i++){
pte_t pte = pagetable[i];
if((pte & PTE_V) && (pte & (PTE_R|PTE_W|PTE_X)) == 0){
// this PTE points to a lower-level page table.
uint64 child = PTE2PA(pte);
freewalk((pagetable_t)child);
pagetable[i] = 0;
} else if(pte & PTE_V){
panic("freewalk: leaf");
}
}
kfree((void*)pagetable);
}可以看到,若panic,则对应的pte的PTE_R,W,X均有效,即该pte没有释放。因此,需要在proc_freepagetable处unmap了。
发现方法:(呃呃,我搜了,确实不会gdb)
gdb设置freewalk断点,continue后通过backtrace找函数调用栈可以发现。
Print a page table (easy)
没什么好说的,对着提示写递归就行。
void _vmprint_level(pagetable_t pagetable, int level){
if(level>2){
return;
}
// there are 2^9 = 512 PTEs in a page table.
for(int i = 0; i < 512; i++){
pte_t pte = pagetable[i];
if(pte & PTE_V){
// this PTE points to a lower-level page table.
for(int i = 0;i <= level;++i){
printf(" ..");
}
uint64 child = PTE2PA(pte);
printf("%d: pte %p pa %p\n", i, pte, child);
_vmprint_level((pagetable_t)child, level+1);
}
}
}
void vmprint(pagetable_t pagetable){
printf("page table %p\n", pagetable);
_vmprint_level(pagetable, 0);
}坑点在于不能先写这个再写speed up…
speed up会创建必要的内核页表映射,若没有写speed up部分,print会缺少一页,也就是speed up创建的USYSCALL映射页。
Detecting which pages have been accessed (hard)
这题需要跨文件来使用walk函数,但walk函数已经被封装而不能直接使用,因此封装了一下写了mywalk函数:
kernel/vm.c
pte_t *
my_walk(pagetable_t pagetable, uint64 va, int alloc){
return walk(pagetable, va, alloc);
}kernel/sysproc.c
#ifdef LAB_PGTBL
void my_pgacess_walk(uint64 va, int num, int* buf){
struct proc* p = myproc();
vmprint(p->pagetable);
for(int i =0;i<num;++i){
pte_t* pte = my_walk(p->pagetable, va, 0);
if(*pte & PTE_A){
(*buf) |=(1<<i);
(*pte) &= ~(PTE_A);
printf("pte: %p\n", *pte);
}
va+=PGSIZE;
}
}
int
sys_pgaccess(void)
{
uint64 va, buf;
int num;
int tempbuf = 0;
if(argaddr(0, &va) < 0 || argint(1, &num) <0 || argaddr(2, &buf) <0)
return -1;
struct proc* p = myproc();
my_pgacess_walk(va, num, &tempbuf);
printf("buf: %p\n", (uint64)tempbuf);
if(copyout(p->pagetable, buf, (char*)&tempbuf, sizeof(tempbuf))<0){
return -1;
}
return 0;
}
#endif
